301.03 - Data parallelism
Data-Parallel Programming
Until now we talked about task-parallel programming: distribution of computations over parallel nodes.
Data-parallel programming distributes data across parallel nodes.
The simple form of data parallelization is the parallel for loop. Example: initializing the array values:
def initializeArray(xs: Array[Int])(v: Int): Unit = {
for (i <- (0 until xs.length).par) {
xs(i) = v
}
}Adding .par to the Range converts it to a Parallel Range . This parallel for loop doesn't return any values, it only acts through side-effects such as writing to an array. Because of the side-effects, the parallel for loop only works if the body of the loop writes to different areas of the array, which is the case. If the body of the look would do something like this, instead:
xs(0) = vthe result of the computation would be non-deterministic.
Another example of parallel for loop is visualizing a Mandelbrot Set. This is rendering a set of complex numbers in the plane for which the sequence: $$z_{n+1} = z_n^2 + c$$ does not approach infinity.
Data-parallel Operations
In Scala, most collection operations can be made data-parallel:
(1 until 100).par
.filter(n => n %3 == 0)
.count(n => n.toString == n.toString.reverse)The filter and count operations above are parallelized. However, some collection operations cannot be parallelized. For instance, the implementation of sum using foldLeft:
def sum(xs: Array[Int]): Int = {
xs.par.foldLeft(0)(_ + _)
}Despite the fact that the array has been made data-parallel, the execution of the foldLeft is still sequential. The foldLeft has the following signature:
def foldLeft[B](z: B)(f: (B, A) => B): Bour collection: B B B B B will be folded as:
A A A B -> B -> B -> ... -> B
In order to calculate the value at step x we must have the value at step x-1. For this reason, foldLeft cannot be easily parallelized.
A variation of the operation, called fold can be implemented in parallel:
def fold[A](z: A)(f: (A, A) => A): ABecause both arguments of the folding function take the same type of argument, the operation can be parallelized:
A A -> A -> A A -> A A
This is very similar to the reduction tree that we studied before.
Many other operations can be made data-parallel based on fold. For instance:
def sum(xs: Array[Int]): Int = {
xs.par.fold(0)(_ + _)
}Another example is the max function:
def max(xs: Array[Int]): Int = {
xs.par.fold(Int.MinValue)(math.max)
}The common things about sum and max is that:
- the "neutral" element (0 for addition, MinValue for max) acts as identity: f(x, id) = x
- the folding function is associative: f(x, f(y, z)) = f(f(x,y), z)
The id element and the folding function constitute a monoid.
Commutativity isn't necessary for the fold operation.
The fold operation has a big limitation: the accumulator must have the same type as the collection elements. For instance, something like this wouldn't even compile:
val a = Array('A', 'X', 'M', 'P')
val vowelCount
= a.par.fold(0)((count, ch)=>if(isVowel(ch)) count+1 else count)because the accumulator is an Int while the collection elements are chars.
We can define, though, anoother function: aggregate with the following signature:
def aggregate[B](z: B)(f: (B, A) => B, g: (B, B) => B): BA A A B -> B -> B ... -> B -> B B -> B -> B ... -> B A A A
This is a combination of foldLeft (f) and fold (g) . We can now do:
val a = Array('A', 'X', 'M', 'P')
val vowelCount
= a.par.aggregate(0)
((count, ch)=>if(isVowel(ch)) count+1 else count, _ + _)Again, the parallel reduction operator + and the neutral value 0 must for a monoid.
Operations such as fold, sum, aggregate are accessor (read-only) operations. Other operations, such as map, filter, flatMap and groupBy are transformer (read-write) combinators.
Parallel collections
Scala Collections hierarchy
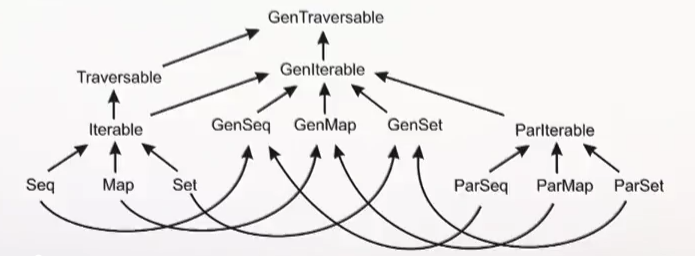
1) Traversable[T] - collection of elements of type T with operations implemented using foreach; 2) Iterable[T] - collection of elements of type T with operations implemented using iterator; 3) Seq[T] - ordered sequence of elements of type T; 4) Set[T] - set of elements of type T (no duplicates); 5) Map[K, V] - maps of keys of type K to values of type V (no duplicate keys);
Parallel Collections hierarchy
ParIterable[T], ParSeq[T], ParSet[T], ParMap[K, V] are the parallel counterparts of the collections above.
For code agnostic to parallelism there are generic counterparts of the above collections: GenIterable[T], GenSeq[T], GenSet[T], GenMap[K, V]:
def largestPalindrome(xs: GenSeq[Int]): Int = {
xs.aggregate(Int.MinValue)(
(largest, n) =>
if ((n > largest) && (n.toString == n.toString.reverse))
n else largest, math.max
)
}
val array = (0 until 1000000).toArray
// sequential
largestPalindrom(array)
// parallel
largestPalindrom(array.par)Other parallelizable collections include ParArray[T], ParVector[T] and ParRange., as well as ParHashSet[T], ParHashMap[K, V] and ParTrieMap[K, V].
The conversion from a regular collection to a parallelizable collection (achieved by invoking .par) takes some processing time. Parallel collections should be used only if there's an overall benefit.
Another example, the intersection of two generic sets:
def intersection(a: GenSet[Int], b: GenSet[Int]): Set[Int] = {
val result = mutable.Set[Int]()
for (x <- a) if (b contains x) result += x
result
}
intersection((0 until 10000).toSet, (0 until 10000 by 4).toSet)
intersection((0 until 10000).par.toSet, (0 until 10000 by 4).par.toSet)This program is NOT correct, because result is mutable and will be accessed simultaneously by multiple threads.
A possible solution would be to use a thread-safe implementation of the result Set:
def intersection(a: GenSet[Int], b: GenSet[Int]): Set[Int] = {
val result = new ConcurrentSkipListSet[Int]()
for (x <- a) if (b contains x) result += x
result
}
intersection((0 until 10000).toSet, (0 until 10000 by 4).toSet)
intersection((0 until 10000).par.toSet, (0 until 10000 by 4).par.toSet)An even better solution is to avoid mutation altogether, by using the right combinators (in this case the filter combinator):
def intersection(a: GenSet[Int], b: GenSet[Int]): Set[Int] = {
if (a.size < b.size) a.filter(b(_)) else b.filter(a(_))
}
intersection((0 until 10000).toSet, (0 until 10000 by 4).toSet)
intersection((0 until 10000).par.toSet, (0 until 10000 by 4).par.toSet)Never modify common memory locations without proper synchronization
Never modify a parallel collection on which a data-parallel operation is in progress
An exception to the above rules is the TrieMap[K, V] collection, that takes a snapshot of the original data either on demand or when iterating over it. This allows separating the processing such as reads are done from the snapshot, while writes operate on the original collection.
Splitters and Combiners
Iterators
Each Iterable collection can create its own Iterator object:
trait Iterator[A] {
def next: A
def hasNext: Boolean
}
def iterator: Iterator[A] // on each collectionThe Iterator contract:
- next should only be called if hasNext returns true
- after hasNext returns false, it will always return false
Splitters
Splitters are counterpart of Iterators used for parallel programming.
trait Splitter[A] extends Iterator[A] {
def split: Seq[Splitter[A]]
def remaining: Int // estimate on the number of remaining elements
}
def splitter: Splitter[A] // on each *parallel* collectionThe Splitter contract:
- after calling split, the original Splitter is left in an undefined state
- the resulting Splitters traverse disjoint regions of the original Splitter
- remaining is an estimate of the number of remaining elements
- split is an efficient operation O(log n) or better
Here is how you can enhance a Splitter with the fold operation we saw before:
def fold(z: A)(f: (A, A) => A): A = {
if (remaining < threshold) foldLeft(z)(f)
else {
val children = for (child <- split) yield task {child.fold(z)(f) }
children.map(_.join()).foldLeft(z)(f) // foldLeft merges the partial results
}
}Builders
Builders are abstractions used for creating new collections.:
// A is the type of elements that we can add to the Builder and Repr is the
// type of the collection that the Builder creates
trait Builder[A, Repr] {
def +=(elem: A): Builder[A, Repr]
def result: Repr
}
def newBuilder: Builder[A, Repr] // on each collectionThe Builder contract:
- calling result returns a collection of type Repr, containing the elemnts that have been previously added with +=
- calling result leaves the Builder in an undefined state
Here is an example on how the filter method can be implemented on collections:
def filter(p: T => Boolean): Traversable[T] = {
val b = newBuilder
for(x <- this) { if p(x) b += x }
b.result
}Combiners
A Combiner is a parallel version of a Builder.
trait Combiner[A, Repr] extends Builder[A, Repr] = {
def combine(that: Combiner[A, Repr]): Combiner[A, Repr]
}
def newCombiner = Combiner[T, Repr] // on each *parallel* collectionThe Combiner contract:
- calling combine returns a new Combiner that contains elements of the input combiners
- calling combine leaves both original Combiners in an undefined state
- combine is an efficient operation O(log n) or better